The Languages page states that 1800+ hours of audio has been recorded in Bengali. However only 1268 hours of audio has been released so far.
Note that 1800+ hours of audio had been recorded before CV-12, 13 & 14 was released. But no version of the dataset contains 1800 hours of audio. The latest dataset (CV-14) contains 1268 hours of Bengali audio.
Why is the 600 hours of audio not being released? Or, is it that only 1200 hours of audio has been recorded so far but the system is showing 1800 hours because of a glitch/bug?
As you can see above, between v11 and 12 they are recorded but not validated. So the community should go to the “listen” page and validate (or invalidate) them.
BTW, the recordings are actually released, meaning they are under the clips directory. On the other hand, they are not in train/dev/test splits.
Hope this helps.
Edit:
You can check your dataset status in general and in detail with the following tools: Common Voice Metadata Viewer - To see how it is advancing in time. Common Voice Dataset Analyzer - To get deeper statistics per dataset release.
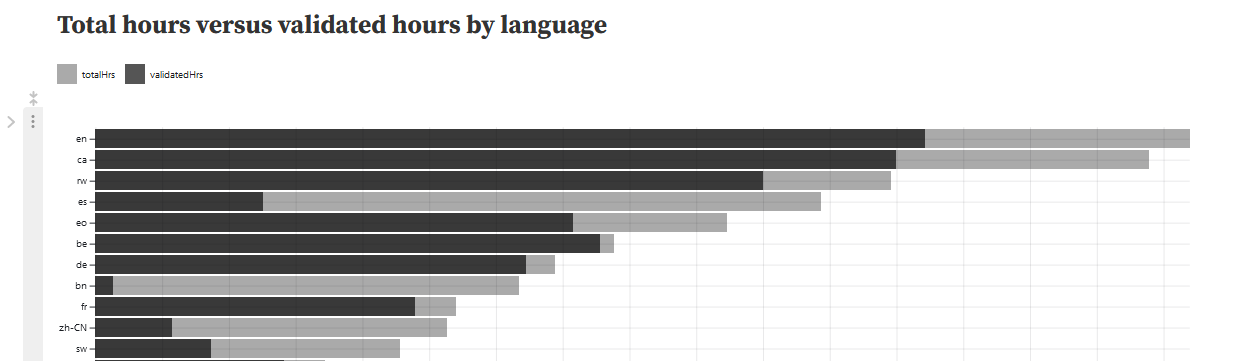
@bozden’s response also matches what I’m seeing in the visualisation of the v14 dataset - Bangla / Bengali has a lot of recorded audio, but only a small amount of validated audio. It’s still there in the dataset, but it’s not in the training splits.
I remember that the length on the stat page is estimated (a predefined time x total clip numbers) and not the actual length of the clips in sum. Not sure if it’s still the case.
If I understand it correctly, currently, the duration of all recordings is calculated in time to remedy perceptive issues related to this. On the other hand, when I analyze the downloaded data, there are some discrepancies, <1%, but they exist. I could not analyze that part yet.
Perhaps @jesslynnrose can give a definitive answer to this…