@bozden Hey Bülent  , please accept my apology for not catching all your proposal upfront…
, please accept my apology for not catching all your proposal upfront…
I’ll retake your message and ask  …I apologize if my question could be seen as rude, it’s not the point, I try to stay on the point of PRO/CONS, and of course I don’t try to hurt/offense/[put whatever hurtful action] you.
…I apologize if my question could be seen as rude, it’s not the point, I try to stay on the point of PRO/CONS, and of course I don’t try to hurt/offense/[put whatever hurtful action] you.
In my opinion, the medium for documentation usually defines the structure. When second version of the Community Playbook came to review, I suggested the use of readthedocs.io, to keep the whole documentation, which supports github linking and localization.
Could you please elaborate In my opinion, the medium for documentation usually defines the structure.? Do you mean that the tool we use format the way we build the doc, less than a design decision ? And, as I think you have much more experience than me in this matter, what are the consequence for project(s)? (either of any project or for this project, the easiest answer for you  )
)
For example, all .md files would be removed and all available in ONE place, with auto table and logical structure, instead of having to go inside each and every repo, looking for the needle in the haystack ? (No, I don’t speak from personal experience  )
)
Most of the Mozilla projects are/were there already, e.g. Welcome to DeepSpeech’s documentation! — Mozilla DeepSpeech 0.10.0-alpha.3 documentation
In such an environment, one can divide it to different user levels, let the language communities give better examples/directions (e.g. replacing the dinosaurs in CV), localized to their needs.
When you say one can divide it to different user levels, you mean that the structure of the help files can be [more] easily divided [than in a raw .MD file] ? By this, I mean that it’s not automatic, it is still a ‘human that decide for the layout’s decision’ ?
Indeed, I fell that it could be interesting, but I didn’t find proof or evidence that it’s better… I mean, I’m not used to this tool, so I don’t grab the ‘wonderful feature that make it a killer app’.
On the other hand, to anticipate counter debate, is it a good idea to add another player (the external website) for maintenance and documentation purpose ?
This is one big step thou, which would need a large team from locales and many man hours.
I’m with @mkohler to keep specifics of one repo in that repo. Repositories have different people/teams who make regular changes.
Isn’t it a counterargument for exterior doc repo/website, and thus for having doc maintained ‘inside the repo’ ? Don’t get me wrong, I agree with having specific things in deeper repo… But again, will community/developers be willing to go to a separate website for documentation reading and/or writing ? …IMHO, it must have a good incentive to carry people to switch… (…and that’s why I’m asking all this! to understand!)
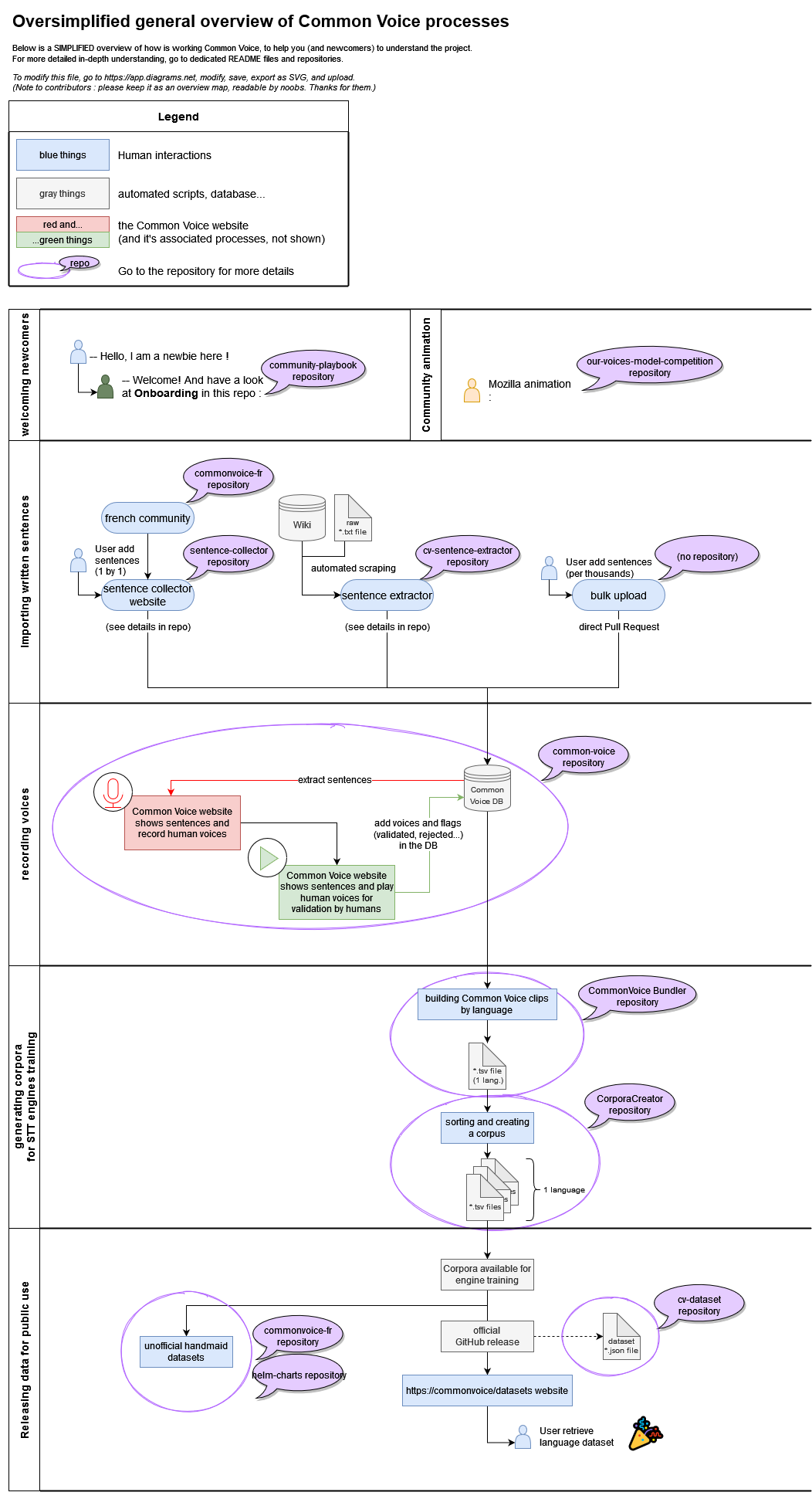
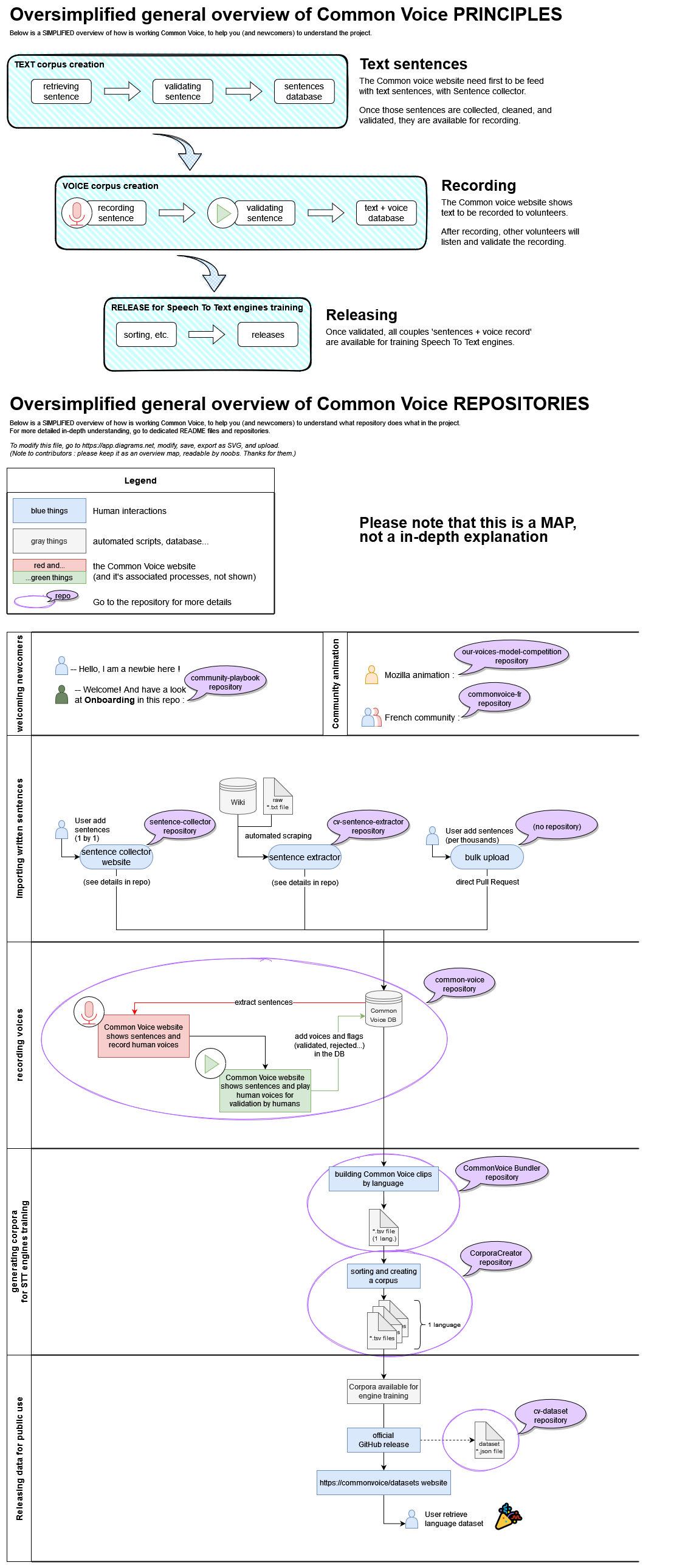
But I feel the need of high level graph on how they all fit together, each box directing to individual repos.
OK with that !
Workflows towards different target audiences, like:
- General public: Contribution
- New teams: New language addition
- Teams: How to analyze/make better (from sentence selection to gender equality)
- Technical (modelers/coders): A simplified version of all workflows with repos, inc. release
- …
I don’t get it. I mean, I understand the idea (different target = different explanation), but not how to implement it in a README.md file. …At least, as it is actually build. But I think it’s a good idea, so how to do it ?
Although many repos also have good docs, I find myself decoding the “re” in code lines to understand what it really does…
Again, I don’t get it… what’s the re ?
EDIT : after re-reading for [choose N, with N tend to infinite]'th time, you mean the REmarks in the code ? Thus, if it’s the point, I didn’t understood how http://readthedocs.io/ generate auto-documentation from code…  If it’s doing it ?!
If it’s doing it ?!
Maybe we can start a topic on “how we can compile a new documentation”?
I also don’t like how it is on the current CV web. About is too much to read, the most basic (and the most important) stuff in “contribution criteria” is very deep and not recognizable, etc.
I agree on that… But (shoot fired) I think the actual README.md files are worth 
 …
…  More seriously, that’s why I’m trying hard to build something more newbie friendly, because
More seriously, that’s why I’m trying hard to build something more newbie friendly, because writing code is not the only way to help. And thus, I want to help  .
.
Thanks for your time to 
 help me to catch it !
help me to catch it !
 or rotten
or rotten  to tell me what you think !
to tell me what you think ! But IMHO:
But IMHO: microphone and
microphone and  sound icons were as simple as needed, and that you’d say that
sound icons were as simple as needed, and that you’d say that 
 work in progress
work in progress 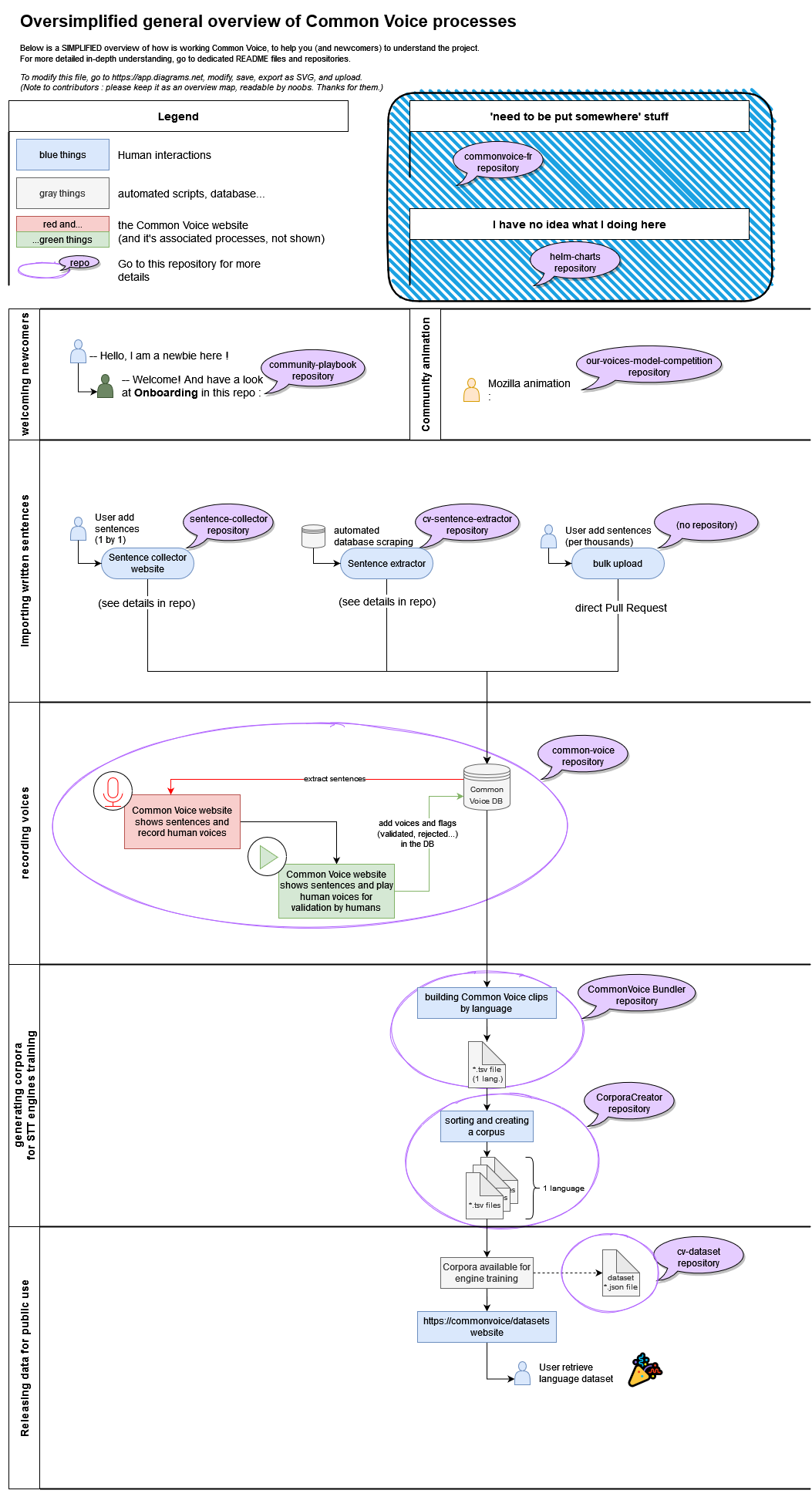

{kind=link}