Hello,
I am new here and I’m finetuning the trained model checkpoint Tacotron2 from the branch 20a6ab3d61.
I am using the french dataset from M-AI-Labs.
The used config file is the one that comes with teh branch 20a6ab3d61, I only changed teh following :
CONFIG[“audio”][‘sample_rate’] = 16000 # to fit my dataset audio
CONFIG[“phoneme_language”] = "fr-fr # french phoneme
CONFIG[“prenet_type”] = “bn” #because of my initial checkpoint
CONFIG[“prenet_dropout”] = True #because of my initial checkpoint
CONFIG[“seq_len_norm”] = True # beacause of the different length of the audios in my dataset . ( I think )
After 5000 steps of training I have the following results :


when I test the model with french short sentence the result is acceptable and I believe it will emprove a lot after maybe another 10 000 steps.
however I think it that the model have a problem with long sentences !
I would be gratefull if someone can help me answer the following quetions :
-
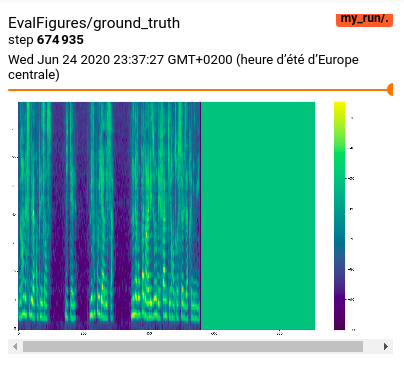
first and most importantly ! what the heck is that green erea in the ground truth !!
image|404x367
I believe that it is causing the problem with the long sentences , is there any solutions ? ( I checked many simples of my data set with CheckSpectrograms.ipynb and everything seems good there ! ) -
the model Tacotron2 checkpoint_670000.pth.tar that I am finetuning is trained on a dataset with audio of “sample_rate”: 22 050, however my dataset’s audio “sample_rate”: 16 000 ,
Can that be a problem ? -
how to set my test sentence for tensorboard in “test_sentences_file” ? ( I tried to create a text file and write it’s path in “test_sentences_file” param but it did not work ) ( I need to manually set the test sentences because I think the model is creating english sentences not french ) ?
-
I am using google colab for the training so I’d like to know if it can effect the results to stop each 11 hours and re-train from the last checkpoint instead of training without interruptions ?
-
The newly created model read number in english with a french accent xD ! any suggestions ?
Any other suggestions or tips are very appreciated !
thanks in advance !!

{kind=link}