I’m sharing with the kab contributors on our FB page some stats about the kab corpus. The corpus was analyzed after tokenization and pos tagging using NLTK Perceptron Tagger. I used a model I have already generated from another corpus.
For graphs and networks I used: matplotlib, numpy, networkx and pylab
I analyzed:
Word length
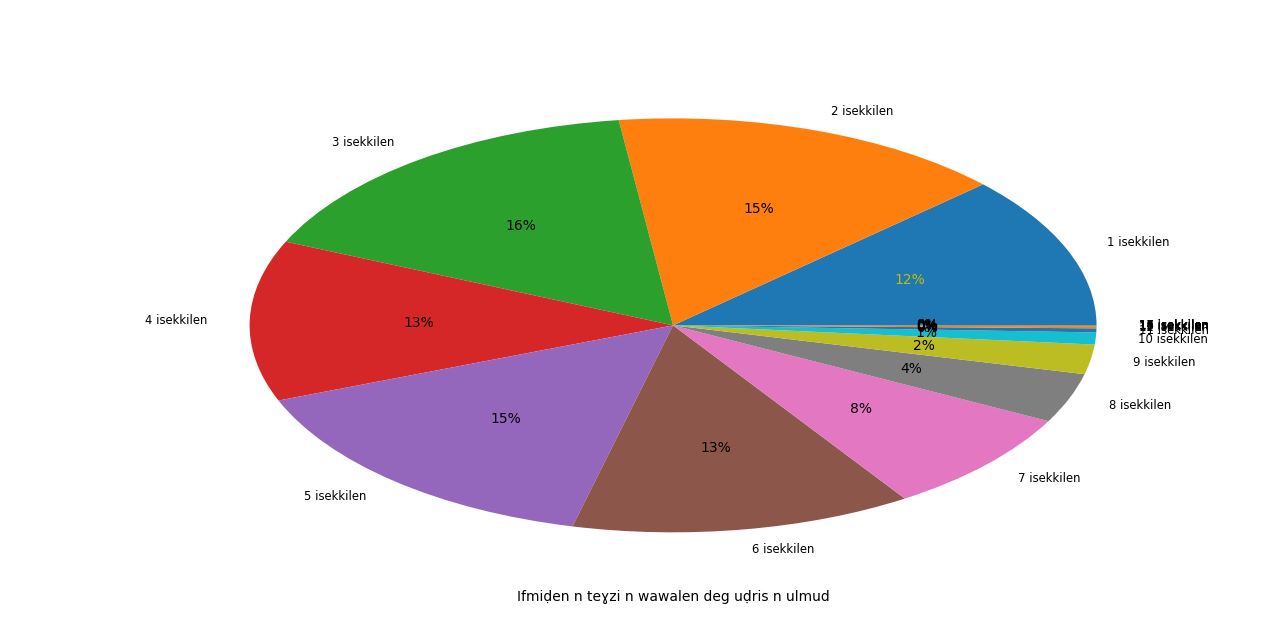
Sentence lenght
Grammatical classes (tags)
Punctuation VS Alphabet
Verbs/Aspect
Verb occurence
Word Occurence
We use these stats to avoid repetitive words and syntatic forms.






 I’ll check if I uploaded the last updates (mozillakab on github and I use mostly French to explain/describe things)
I’ll check if I uploaded the last updates (mozillakab on github and I use mostly French to explain/describe things)