Hey,
I’ve been running TTS on russian common voice dataset.
Tensorbord shows that everything is looking good. However, TestFigures in IMAGE tab has no diagonal…



Did you give russian test sentences?
check FAQ for using TTS in a new language
BTW Isn’t it a multi speaker dataset?
test_sentences.txt has 4 lines with russian text. Shall I put it into root TTS folder or to output_path?
it’s multi speaker dataset, but multi speaker feature is disabled.
you need to set the relevant field in the config file. Check the FAQ once more.
My config.json
{
"model": "Tacotron", // one of the model in models/
"run_name": "common_voice",
"run_description": "tacotron cosntant stf parameters",
// AUDIO PARAMETERS
"audio":{
// Audio processing parameters
"num_mels": 80, // size of the mel spec frame.
"num_freq": 1025, // number of stft frequency levels. Size of the linear spectogram frame.
"sample_rate": 22050, // DATASET-RELATED: wav sample-rate. If different than the original data, it is resampled.
"win_length": 1024, // stft window length in ms.
"hop_length": 256, // stft window hop-lengh in ms.
"frame_length_ms": null, // stft window length in ms.If null, 'win_length' is used.
"frame_shift_ms": null, // stft window hop-lengh in ms. If null, 'hop_length' is used.
"preemphasis": 0.98, // pre-emphasis to reduce spec noise and make it more structured. If 0.0, no -pre-emphasis.
"min_level_db": -100, // normalization range
"ref_level_db": 20, // reference level db, theoretically 20db is the sound of air.
"power": 1.5, // value to sharpen wav signals after GL algorithm.
"griffin_lim_iters": 30,// #griffin-lim iterations. 30-60 is a good range. Larger the value, slower the generation.
// Normalization parameters
"signal_norm": true, // normalize the spec values in range [0, 1]
"symmetric_norm": true, // move normalization to range [-1, 1]
"max_norm": 4.0, // scale normalization to range [-max_norm, max_norm] or [0, max_norm]
"clip_norm": true, // clip normalized values into the range.
"mel_fmin": 0.0, // minimum freq level for mel-spec. ~50 for male and ~95 for female voices. Tune for dataset!!
"mel_fmax": 8000.0, // maximum freq level for mel-spec. Tune for dataset!!
"do_trim_silence": true, // enable trimming of slience of audio as you load it. LJspeech (false), TWEB (false), Nancy (true)
"trim_db": 60 // threshold for timming silence. Set this according to your dataset.
},
// VOCABULARY PARAMETERS
// if custom character set is not defined,
// default set in symbols.py is used
"characters":{
"pad": "_",
"eos": "~",
"bos": "^",
"characters": "АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюяёЁ",
"punctuations":"!'(),-.:;? ",
"phonemes":"iyɨʉɯuɪʏʊeøɘəɵɤoɛœɜɞʌɔæɐaɶɑɒᵻʘɓǀɗǃʄǂɠǁʛpbtdʈɖcɟkɡqɢʔɴŋɲɳnɱmʙrʀⱱɾɽɸβfvθðszʃʒʂʐçʝxɣχʁħʕhɦɬɮʋɹɻjɰlɭʎʟˈˌːˑʍwɥʜʢʡɕʑɺɧɚ˞ɫ"
},
// DISTRIBUTED TRAINING
"distributed":{
"backend": "nccl",
"url": "tcp:\/\/localhost:54321"
},
"reinit_layers": [], // give a list of layer names to restore from the given checkpoint. If not defined, it reloads all heuristically matching layers.
// TRAINING
"batch_size": 32, // Batch size for training. Lower values than 32 might cause hard to learn attention. It is overwritten by 'gradual_training'.
"eval_batch_size":16,
"r": 7, // Number of decoder frames to predict per iteration. Set the initial values if gradual training is enabled.
"gradual_training": [[0, 7, 32], [1, 5, 32], [50000, 3, 32], [130000, 2, 16], [290000, 1, 16]], // ONLY TACOTRON - set gradual training steps [first_step, r, batch_size]. If it is null, gradual training is disabled.
"loss_masking": true, // enable / disable loss masking against the sequence padding.
// VALIDATION
"run_eval": true,
"test_delay_epochs": 10, //Until attention is aligned, testing only wastes computation time.
"test_sentences_file": "test_sentences.txt", // set a file to load sentences to be used for testing. If it is null then we use default english sentences.
// OPTIMIZER
"noam_schedule": false, // use noam warmup and lr schedule.
"grad_clip": 1.0, // upper limit for gradients for clipping.
"epochs": 1000, // total number of epochs to train.
"lr": 0.0002, // Initial learning rate. If Noam decay is active, maximum learning rate.
"wd": 0.000001, // Weight decay weight.
"warmup_steps": 4000, // Noam decay steps to increase the learning rate from 0 to "lr"
"seq_len_norm": false, // Normalize eash sample loss with its length to alleviate imbalanced datasets. Use it if your dataset is small or has skewed distribution of sequence lengths.
// TACOTRON PRENET
"memory_size": -1, // ONLY TACOTRON - size of the memory queue used fro storing last decoder predictions for auto-regression. If < 0, memory queue is disabled and decoder only uses the last prediction frame.
"prenet_type": "original", // "original" or "bn".
"prenet_dropout": true, // enable/disable dropout at prenet.
// ATTENTION
"attention_type": "original", // 'original' or 'graves'
"attention_heads": 4, // number of attention heads (only for 'graves')
"attention_norm": "sigmoid", // softmax or sigmoid. Suggested to use softmax for Tacotron2 and sigmoid for Tacotron.
"windowing": false, // Enables attention windowing. Used only in eval mode.
"use_forward_attn": false, // if it uses forward attention. In general, it aligns faster.
"forward_attn_mask": false, // Additional masking forcing monotonicity only in eval mode.
"transition_agent": false, // enable/disable transition agent of forward attention.
"location_attn": true, // enable_disable location sensitive attention. It is enabled for TACOTRON by default.
"bidirectional_decoder": false, // use https://arxiv.org/abs/1907.09006. Use it, if attention does not work well with your dataset.
// STOPNET
"stopnet": true, // Train stopnet predicting the end of synthesis.
"separate_stopnet": true, // Train stopnet seperately if 'stopnet==true'. It prevents stopnet loss to influence the rest of the model. It causes a better model, but it trains SLOWER.
// TENSORBOARD and LOGGING
"print_step": 25, // Number of steps to log traning on console.
"save_step": 350, // Number of training steps expected to save traninpg stats and checkpoints.
"checkpoint": true, // If true, it saves checkpoints per "save_step"
"tb_model_param_stats": false, // true, plots param stats per layer on tensorboard. Might be memory consuming, but good for debugging.
// DATA LOADING
"text_cleaner": "basic_cleaners",
"enable_eos_bos_chars": false, // enable/disable beginning of sentence and end of sentence chars.
"num_loader_workers": 8, // number of training data loader processes. Don't set it too big. 4-8 are good values.
"num_val_loader_workers": 8, // number of evaluation data loader processes.
"batch_group_size": 0, //Number of batches to shuffle after bucketing.
"min_seq_len": 0, // DATASET-RELATED: minimum text length to use in training
"max_seq_len": 150, // DATASET-RELATED: maximum text length
// PATHS
"output_path": "trainings/",
// PHONEMES
"phoneme_cache_path": "mozilla_ru_phonemes_2_1", // phoneme computation is slow, therefore, it caches results in the given folder.
"use_phonemes": false, // use phonemes instead of raw characters. It is suggested for better pronounciation.
"phoneme_language": "ru", // depending on your target language, pick one from https://github.com/bootphon/phonemizer#languages
// MULTI-SPEAKER and GST
"use_speaker_embedding": false, // use speaker embedding to enable multi-speaker learning.
"style_wav_for_test": null, // path to style wav file to be used in TacotronGST inference.
"use_gst": false, // TACOTRON ONLY: use global style tokens
// DATASETS
"datasets": // List of datasets. They all merged and they get different speaker_ids.
[
{
"name": "common_voice",
"path": "/audio",
"meta_file_train": "validated.tsv",
"meta_file_val": "test.tsv"
}
]
}
utils/text/symbols.py
...
_characters = 'АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюяёЁ!\'(),-.:;? '
...
Made ~300,000 steps. Model looks healthy, but when I run server.py and try to synthesize something I receive messed audio.


I suspect that it might happen because of difference symbols of config.json and symbols.py
config.json:
"characters": "АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюяёЁ",
symbols.py:
_characters = 'АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюяёЁ!\'(),-.:;? '
You can ignore the symbols.py if you are using characters in config.json. If you inspect symbols.py there is a make_symbols functions, which builds the symbols from the config.json. And since you have
"characters":"АБВГДЕЖЗИЙКЛМНОПРСТУФХЦЧШЭЮЯабвгдежзийклмнопрстуфхцчшщъыьэюяёЁ",
"punctuations":"!'(),-.:;? ",
in your config.json, it should work just fine.
I think the problem here is that you are using a multispeaker dataset but you have speaker embeddings disabled… see config “use_speaker_embedding”: false.
Maybe you should try to train a single speaker dataset first and see if that works out for you.
Can’t ignore symbols.py because it’s used during dataset loading. If I leave symbols.py with english chars it training won’t start because input will be empty…
I mean you dont need to modify symbols.py because symbols.py is using the characters from the config.json
Ok. Cloned tts repo again. Started training again with minor changes in code. Haven’t changed symbols.py file. We will see if it work out



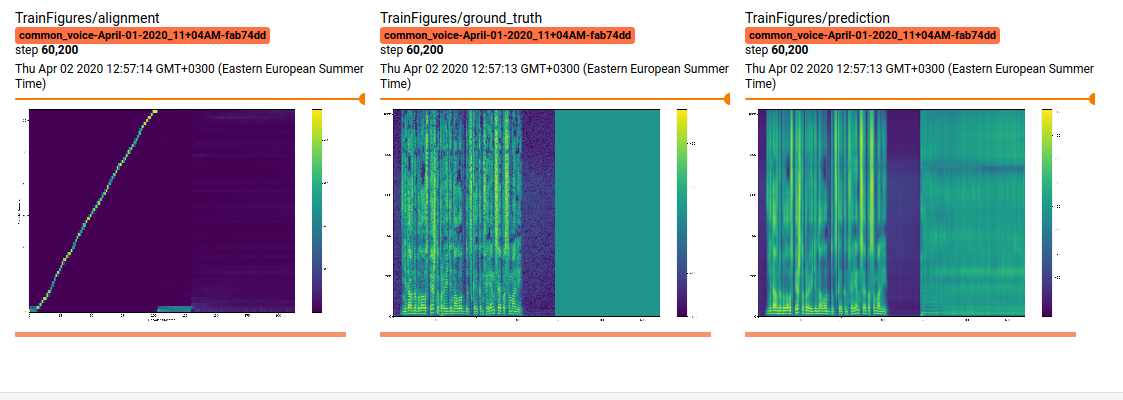
After 100,000 steps.


As I understood the model trained good, but synthesize code might have issue to generate test snippets. I’ll look thru this code
Logs during synthesizing
tts_1 | | > Synthesizing test sentences
tts_1 | | > Decoder stopped with 'max_decoder_steps
tts_1 | | > Decoder stopped with 'max_decoder_steps
tts_1 | | > Decoder stopped with 'max_decoder_steps
tts_1 | | > Decoder stopped with 'max_decoder_steps
Are you still training on the common_voice dataset? I listened to some of the audio and would say the quality is not fit to train a tts system because of the noise in it.
1 Like
rnnoise removes a good amount of background noises (computer fan, electric hum, etc.).
Is there any other options for russian? I wouldn’t say clips in common voice are noisy. At least in russian dataset…
training above looks broken. There might be a mismatch or a different problem in test time.
have you tried rnnnoise for LJSpeech?